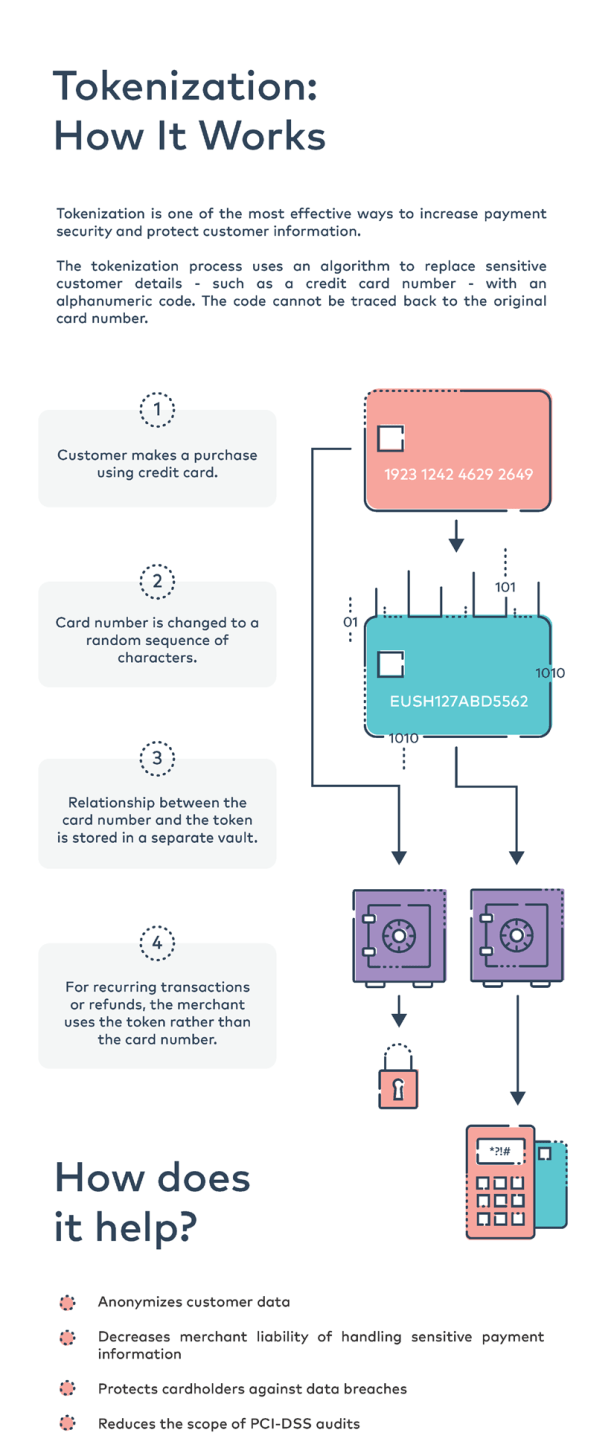
Data Culture is a passport you need to survive in this new digital world, where decisions are driven by data rather than solely on assumptions and past experiences.
Data culture is a journey, where we need to constantly keep working on it, and it will keep on improving. Data is all around us. It is in the form of numbers, spreadsheets, databases, pictures, videos, and many other things. Organisations are now using data and leveraging it to derive impact and growth. Data is the backbone, and a data-driven culture is critical for organisations to survive and expand. A data-driven culture is about replacing the gut feeling to make decisions with facts and assumptions. A company is said to have a data-driven culture when people are clear about the driver metrics they are responsible for and how those metrics move the Key Performance Indicators – KPIs. There needs to be data democratization, i.e., the information is accessible to the average user. The company needs its employees to understand and use data to make decisions based on their roles. It needs citizen analysts, who can do simpler analytics, and are not dependent on the data team for it. The company also needs a Single Source of Truth—when the employees/stakeholders make decisions based on the same data set. It needs to have data governance and Master Data Management in place to maintain uniformity, accuracy, usability, and security of data.
At the very top level, there are four components of data-driven culture—Data Maturity, Data-Driven Leadership, Data Literacy, and Decision-making Process. These 4Ds are essential when building a data-driven culture.
Data Maturity
Data maturity is foundational to data culture. It deals with the raw material, i.e. data, and its management. An organization with good data maturity has high standard data of quality and checks in place to maintain it. For a good level of data maturity, it is important to have metadata management in place and ensure that it is aligned with the KPIs. Similarly, it is necessary to record Data Lineage, which helps in understanding what happened to it since its origin. Other factors that affect data maturity are usability, ease of access, and scalable and agile infrastructure. For example, if a company has an archaic infrastructure in place, it will take too long to access data. In such scenarios, the organization will not use data that is not easily accessible. Further, companies would spend most of their time validating and building alignment rather than on the impact if there is no alignment of the KPIs.
Data-Driven Leadership
Leaders define the culture of any organization. To establish a data culture, leaders must step up and lead by example. A data driven leader asks the right questions and holds his/her teams responsible to ensure that data is being used and a structured process is followed. A data-driven leader sees data as a strategic asset and makes “think and act data” a key strategic priority.
Data Literacy
Companies with a higher data literacy tend to use data to understand their customers better as well as how they use the product. Data literacy is the ability to read, use, digest, and interpret data toward meaningful discussion and conclusion. For an organization, data literacy does not mean that employees have an excellent understanding of using and interpreting data. It calls for everyone to have a certain level of data literacy depending upon their job role and the decisions they need to make. However, it also calls for ensuring that there is no data sceptic.
Decision-making Process
Data needs to be an integral part of that decision-making process to get the most value out of it. Is there a planning mechanism in place to choose between projects to work on or if there is a lookback mechanism to review the decisions? Most organisations do not have a systematic, data-driven decision-making process.
Using facts and evidence in the workplace is a good way to guide a company’s decisions and track outcomes. When everyone within an organisation incorporates data and information in their day-to-day activities, they develop a culture that emphasizes and prioritizes data analysis. Cultivating a data-driven culture in our workplace can improve outcomes across the organization and ensures a strategic plan for achieving goals.