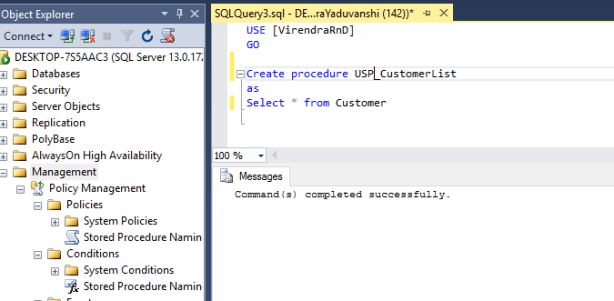
I hope, all SQL Server DBA or Developer have faced the scenario where they have to copy only SQL Server Database objects without data. To do this, commonly DBA/Developer script-out source database using generate script wizard and run that script at targeted instance. I have seen very few people are aware about a feature named as “DAC Package” which is available from SQL server 2008 R2 onwards. Using DAC Package, we can take all objects backup without data and restore it to any other instance. Here are the step-by-step details as
Step -1 ) Connect SQL Server instance using SSMS, from Object explorer, Right click on database-àTasksàExtract Data-tier Application
It will open Extract Data-tier Application wizard, click on next, Set Properties option will be open
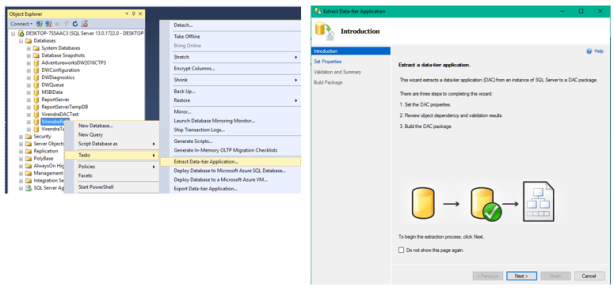
Step 2) Just Set DAC Package file location and click on next, Check Validation and Summary, then Next

Step 3) Click on Finish, DAC Package will be create at specified location

Now you can restore this DAC package anywhere you wanted. Steps are as below
Step 4) Connect your SQL Instance using SSMS where you want to restore this DAC Package, Right click on Databasesà Deploy Data-tier Application…, Deploy wizard will be open, Select Next,

Step 5) Browse DAC package then click on next, Change desired Database Name as per requirement, click on next, Just review summary and click on finish,


That’s all , New Database restored without data….
Enjoy J !







 !
!