-
The login auditing is configured to “Failed logins only” by default. This is to record and audit the login failure attempts and is a recommended security best practice. Consider enabling Auditing for failed logins.
-
Use 2048 bit and above to create asymmetric keys.
-
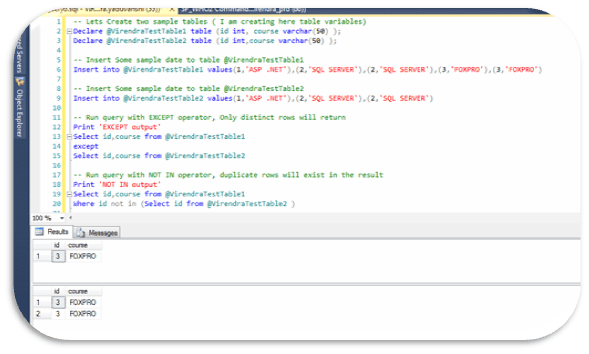
There are SQL Server Agent job steps that use the incorrect brackets to call out tokens. Starting with SQL Server 2005, the token syntax changed, and square brackets – [ ], are no longer used to call out SQL Server Agent job step tokens.
-
Windows Authentication is the default authentication mode, and is much more secure than SQL Server Authentication. Windows Authentication uses Kerberos security protocol, provides password policy enforcement with regard to complexity validation for strong passwords, provides support for account lockout, and supports password expiration.
-
The SQL Server error log contains messages that indicate either the failure of database file autogrow operations or that these operations took a long period of time to complete. An application will have timeouts, or query performance will be decreased, if database file growth happens during regular activity. Enable Instant File Initialization, pre-autogrow the database files to the required size, and use a growth value in absolute size.
-
Review the backup schedules of all critical databases and schedule backups based on the various tolerance levels.
-
If The combination of the affinity mask and affinity I/O mask is incorrect then Configure the affinity mask and affinity I/O mask, such the CPU masks, do not overlap.
-
If the instance of SQL Server has recorded one or more potentially dangerous data inconsistency and data corruption errors in the past then For each one of the affected databases that encountered these errors, perform database consistency checks and take appropriate decision accordingly.
-
Sometimes one or more databases on server that have their data and log files in the same volumes can cause contention for that device and result in poor performance, for this its recomended that the Data and log files should be placed on separate volumes.
-
Inconsistencies that exist in a database can threaten the availability of the entire database or some portions of it for the application. It should be Schedule a DBCC CHECK to perform a consistency check of the problematic database.
-
Never place database files and backup files on the same volume, Always perform backups to a different volume or to a remote location/SAN.
-
Always avoid the Shrink option to manage the database file sizes. Frequent grow and shrink operations can lead to excessive fragmentation and performance issues.
-
If the databases have not CHECKSUM page protection, must need to enable this protection on those databases becausetThe CHECKSUM protection provides a high level of data integrity guarantee when reading database pages from disk.
-
Always try to avoid Auto Close database option disable because for a On systems, repeated opening and closing of the database can result in performance problems and timeout issues.
-
Be informative about Recovery Model, its always recommended that the FULL or BULK-LOGGED recovery model must be used in production servers.
-
There are databases that contain a transaction log file that contains a high number of virtual log files (VLFs).A high number of virtual log files can effect database recovery performance, and consequently, also effect various database maintenance operations that depend on recovery.in this case always Reconfigure the transaction log files for these database. For this please visit http://support.microsoft.com/kb/2028436
-
if default extended event health session is either not active or changed, Reset the changes done to the default extended event health session. The default extended event health session records critical events that can be useful for root cause investigations of certain server conditions.
-
If The max degree of parallelism option is not set to the recommended value, needs to use sp_configure stored procedure to set the max degree of parallelism option to 8 or less.Setting this option to a large value often results in unwanted resource consumption and performance degradation.
-
Incorrect partition alignment can result in adverse I/O performance impacts on SQL Server queries and operations.The hard-disk partitions are configured optimally if partitions have a starting offset of 65536 bytes, or a multiple of 65536 bytes.
-
Using cross-database or distributed transactions on a mirrored database could lead to inconsistencies after a failover.
-
Enabling the guest account allows anonymous connections to your database, The Guest account has access to databases, excluding the master, tempdb, and msdb databases.The guest user cannot be dropped. However, run REVOKE CONNECT FROM GUEST within any database other than the master or tempdb database to revoke the guest user’s CONNECT permission and disable the guest user.
-
If you see presence of Event ID 12, it indicates memory corruption due to a firmware or BIOS issue,This problem can result in system instability and data corruption, for same Check with hardware manufacturer for updated firmware and BIOS.
-
SQL Server reports Event ID 833 when I/O requests take longer than 15 seconds to finish.This indicates a potential problem with the disk I/O subsystem or configuration. This affects SQL Server performance.Use system monitor disk counters to measure disk throughput and response rates. Perform appropriate configuration changes to ensure disk response times are acceptable.
-
Event ID 825 indicates that SQL Server was unable to read data from the disk on the first try.Even though retry was successful, this is usually an indication of an underlying issue that needs investigation and fixing before it becomes worse.
-
If startup parameters for the SQL Server service are incorrect, can result in unexpected SQL Engine behavior and can also cause startup problems.Use the SQL Server Error Log to review the startup parameters that the instance of SQL Server is currently using. Then, use the SQL Configuration Manager to correct these parameters.
-
Its need to set to disable the lightweight pooling option using sp_configure stored procedure,fiber mode scheduling for routine operations can decrease performance by inhibiting the regular benefits of context switching. Furthermore, some components of SQL Server cannot function correctly in fiber mode.
-
If lock is set to a nonzero value, large transactions can encounter the “out of locks” error message, if the value specified is exceeded.Use the sp_configure system stored procedure to change the value of locks to its default setting.
-
The Microsoft Distributed Transaction Coordinator (MSDTC) needs configured properly.
-
The value for the network packet size needs not too high. Excessive memory allocations are needed to support these large network packet size, and can cause memory loss and other stability issues on the server. Be sure, Configuration of the network packet size option to be set as default value.
-
Granting users, who are not Administrators, more than read permission on the Binn folder represents a potential security risk, Only administrators should have full control permission on the Binn folder.
-
Check the permission on the Data folder. Only server administrators and SQL Server service groups should have full control permission on the Data folder. Other users and groups should not have any access.
-
The public database role has EXECUTE permissions on some of the Data Transformation Services (DTS) system stored procedures in the msdb database.A potential security issue occurs if an application uses a login that owns DTS packages to connect to an instance of SQL Server. In this scenario, there is the risk that a SQL injection attack could modify or delete existing DTS packages.Use the sp_dts_secure stored procedure to revoke public access to DTS stored procedures.
-
Every login that is created on the server is a member of the public server role. If this condition is met, every login on the server will have server permissions.Do not grant server permissions to the public server role.
-
Frequently review the Event Log entries that indicate the crash and apply the solutions provided.
-
Enable “Enforce password policy” and “Enforce password expiration” for all the SQL Server logins. Use ALTER LOGIN (Transact-SQL) to configure the password policy for the SQL Server login.Password complexity policies are designed to deter brute force attacks by increasing the number of possible passwords.Disabling the password policy could allow the user to create a SQL Server login with a weak password.
-
The sysadmin role may not be applied correctly. The sysadmin role membership should be granted to limited users. Check the membership and determine if users other than Local System, SQL Server built in admin (SA), SQL Server Engine and Agent service account or service SID are granted sysadmin permission.Grant sysadmin role membership to users who require it. Carefully evaluate the membership of the sysadmin role. Granting sysadmin membership to users who do not require it represents potential security risk.
-
If the Public Role in MSDB is enabled for the SQL Server Agent proxy account, Remove the Public Role in MSDB from the SQL Server Agent proxy account. Typically, the proxy account is given elevated privileges, so someone using the Public Role in MSDB, which has fewer privileges, could take advantage of a higher privilege level.
-
The error log files for SQL Server are very big. This could be due to repetitive errors or information messages.If the error logs are growing due to frequent error conditions, then it will cause stability and availability problems.Best Practices Recommendations Examine the error log to find out why it is growing. If it is expected information, cycle the error logs frequently and configure more error logs to be retained.
-
Do not install SQL Server on a computer that is a domain controller. Installing a SQL Server failover cluster instance on a domain controller is not supported.
-
The SQL Server uses the default values for SQL Server memory configuration [-g parameter] and is also configured to use CLR integration. It may encounter various out-of-memory conditions and associated performance problems, to configure enough memory to handle CLR integration and other needs, use the -g startup parameter.
-
To reduce contention in the tempdb database, increase the number of tempdb data files, and configure the required startup trace flags. Under a heavy load, the tempdb database can become a single point of contention and affect concurrency and performance.
-
Use AES 128-bit and greater to create symmetric keys for data encryption. If AES is not supported by the version of your operating system, use 3DES. Do not create symmetric keys in the databases shipped with SQL Server, such as the master, msdb, model, and tempdb databases.
-
Running the SQL Server Agent service/FDHOST Launcher service under a highly-privileged account represents a potential security risk.Use a specific low-privilege user account or domain account to run the SQL Server Agent service/FDHOST Launcher service.
-
Avoid using unsupported .NET Framework assemblies. If you must use them, always update them in the database when you update them in the GAC.
-
If databases whose collation is different from the model, and therefore, their collations are different from the collation used by the tempdb database, there might be collation conflict errors and unexpected behavior when using different collations to compare data in a user database against the tempdb database. to resolve this, Rebuild the user database to match the model database collation or specify COLLATE when creating temp tables.