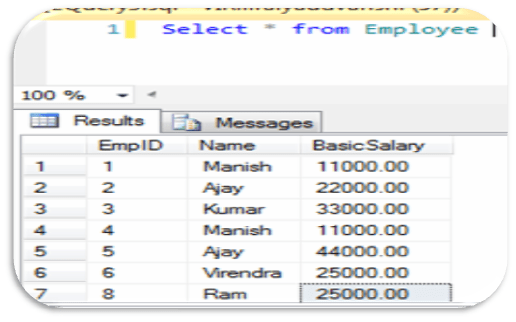
Its very common when a Developer/DBA wanted to see sample of few records, commonly they use SELECT TOP N records from a table being ordered by a column, the query look like as
SELECT TOP N [COLUMNNAME] FROM TABLENAME ORDER BY [COLUMNNAME]
As we know above statement is that if the table has multiple records having the same value as that of the selected list then all those records will not be selected. It will select only one record. But if we want to select all the rows, with same value as the one selected we have to include WITH TIES option in the query. So the query would be
SELECT TOP N [COLUMNNAME] WITH TIES FROM TABLENAME ORDER BY [COLUMNNAME]
For demonstration purpose, below are the step by step details example
Step -1 , Create a Sample Table as PRODUCTLIST
Create table ProductList(ID Int Identity(1,1),PName varchar(30),Price Decimal(10,2))
Step -2 , Insert some sample data
insert into ProductList (Pname,Price) values
(‘Bajaj CFL’, 210.00),
(‘TL’, 135.00),
(‘Table Fan’ ,450.00),
(‘Iron’ ,450.00),
(‘Cable’ ,250.00),o
(‘USB Disk’ ,450.00),
(‘Floppy’ ,120.00),
(‘CD-R’ ,280.00),
(‘CD-W’ ,450.00),
(‘USB Cable’ ,180.00)
For testing, SELECT TOP 3 * from PRODUCTLIST Order by Price DESC will return only 3 records as

But SELECT TOP 3 WITH TIES * from ProductList Order by Price DESC will return more than 3 records as

If we examine about performance, initial one without TIES is more better compare to WITH TIES option, Let see an example here, suppose we have to find top 1 record having maximum price, let see the execution plan

Here we can see, WITH TIES option is performing very poorly compare to initial Select TOP query code, this happened because of ORDER BY clause, to resolve this here we have to create a proper index here for same to get the optimal performance.